GBase 8a 数据库集群是通过主副本机制实现的高可用。当 一个节点完全损坏是,需要在一台新服务器上做节点替换。本文介绍GBase 8a 强制节点离线和节点替换replace。
替换前的一些检查事项,请参考 GBase8a V862版本节点替换前的准备工作和注意事项
其中在确认节点彻底故障时要设置节点不可用状态,然后通过替换命令安装程序,恢复表结构和恢复数据等。
如为85版本,请直接通过主备节点复制目录来恢复。
警告!!!:节点一旦手工设置离线,将不再记录与该节点有关的集群事件(表结构,数据等不一致),也就不能通过集群内部同步机制进行恢复,必须手工进行节点替换。
V95版本的节点替换,请参考 GBase 8a V95版本节点替换操作手顺
目录导航
用途
某个节点判断故障且不可恢复(多为硬件不可恢复故障),已经影响了集群运行,需要人工强制从集群离线。
当后续对硬件修复后,进行节点替换工作。
使用方法
85版本集群离线
gcadmin setnodestate 192.168.174.62 failure86版本集群离线
gcadmin setnodestate 192.168.174.62 [failure| unavailable |normal]其中参数有3个值
- normal是正常,
- failure,故障,记录后续event。如果服务器能恢复,可以设置回normal,集群会自动同步;如确认节点数据丢失,可以再设置为不可用状态。
- unavaliable, 不可用状态,节点已经明确判断不可恢复,数据肯定丢失,此时集群不再记录event,后续请通过【节点替换】功能修复。 如确认肯定没有ddl,dml等会导致event的操作发生,也可强制改成normal。
各状态间均支持转换。
Normal ->failure ->unavaliable
Normal ->unavaliable
区别是,由于unavaliables状态是不记录EVENT的,如果你强行恢复到normal,期间变动会导致数据不一致问题。failure是记录event的,恢复到normal会自动执行同步。
此操作对管理节点和数据节点均生效(只看IP),但不能导致集群出现LOCK状态,比如设置一半或超过一半的管理节点为故障,将报错。
通过如下命令,将节点设置为故障状态。
[gbase@gbase86_1 ~]$ gcadmin setnodestate 192.168.174.62 failure通过如下命令,将节点设置为不可用状态
[gbase@gbase86_1 ~]$ gcadmin setnodestate 192.168.174.62 unavailable通过如下命令,将节点设置为正常状态,强烈建议只从failure状态恢复。
[gbase@gbase86_1 ~]$ gcadmin setnodestate 192.168.174.62 normalIPV6版本用法一样。
[gbase@gbase86_1 ~]$ gcadmin setnodestate 2001::61 failure
[gbase@gbase86_1 ~]$ gcadmin setnodestate 2001::62 normal85恢复
提醒:由于85版本集群已经不再对外发货,强烈建议现场先升级到86版本,再通过集群自带的节点替换工具进行自动恢复。
如下仅用于无法安排集群升级,或者集群数据量少,在客户能接受的停服务的时间内可以完成。
1、安装好操作系统,配置好IP等环境。
2、安装单节点集群
3、然后停下来所有服务 service gcware stop
4、从备用节点进行物理文件恢复
/opt/gbase/gcluster
/opt/gbase/gnode
/var/lib/gware
/etc/corosync/corosync.conf5、启动服务
注意,复制期间如果集群还在进行读写,则建议使用lftp进行mirror增量同步,并在最后一次同步时,将集群设置为只读状态(停止外部加载和后台任务等数据变动业务DML,DDL),可以查询,确保主备机器磁盘文件完全一样。
86节点替换
通过节点替换命令实现。该功能要在任意一个可用管理节点,采用相同版本的gcinstall目录下运行,该功能会自动安装需要的组件。
注意:
- 如果操作系统gbase密码修改过,请参考<8.38.3修改环境变量里的操作系统GBASE密码>章节,先将各个节点环境更新。
- 新节点建议先手工创建gbase操作系统用户,并设置和其它节点一致的密码。
./replace.py --host=192.168.174.62 --rootPwd=111111 –dbaRootPwd=XXXXXXX --overwrite具体命令,请参考—help说明或管理员手册。
其中参数名字在不同的版本可能有不同,比如dbRootPwd,少了个字母a。
注意:
1、替换期间,节点会有一段时间处于readonly状态,系统不可写。此时在同步元数据(库,表结构等),具体时间要根据表的多少判断。
2、故障节点的event,建议在设置状态为unabaliable后进行清理,避免大量event造成集群内部通讯越来越慢。有项目反馈30个管理节点,在event总数量超过12万个时,简单全表count(*)都要10-30秒。而平时只需要1秒以内。 清理方案看后面【清理event】部分。
使用样例
1、检查节点状态,要设置62节点不可用
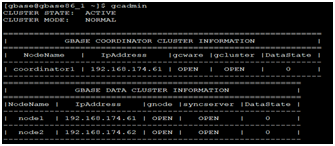
2、节点状态变成UNAVAILAVLE状态
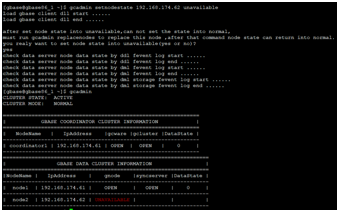
注意:此时建议清理故障节点的event
gcadmin rmdmlstorageevent 2 192.168.174.62
gcadmin rmddlevent 2 192.168.174.62
gcadmin rmdmlevent 2 192.168.174.623、当节点正常后,通过如下命令自动安装节点服务,并恢复数据
注意:操作将检查集群ddl锁,如果有ddl语句在运行,将等待其完成。请确认ddl语句可以很快完成,或者联系业务,杀掉正在运行的ddl语句,避免无法评估等待时间。曾有现场等待了4个小时。
[gbase@gbase86_1 gcinstall]$ ./replace.py --host=192.168.174.62 --rootPwd=111111
192.168.174.62
Are you sure to replace install these nodes ([Y,y]/[N,n])? y
Starting all gcluster nodes...
copy system table from 192.168.174.61 to 192.168.174.62
source ip: 192.168.174.61
target ip: 192.168.174.62
set data restorage flag on node 192.168.174.62 have success stoped
load gbase client dll start ......
load gbase client dll end ......
check node data map and cluster state start ......
check node data map and cluster state end ......
get distribution information start ......
get distribution information end ......
check ip start ......
check ip end ......
switch cluster mode into READONLY start ......
wait all ddl statement stop ......
all ddl statement stoped
switch cluster mode into READONLY end ......
check cluster data state start ......
check coordinator node data state start ......
check coordinator node data state end ......
check data server node data state start ......
check data server node data state by ddl fevent log start ......
check data server node data state by ddl fevent log end ......
check data server node data state by dml fevent log start ......
check data server node data state by dml fevent log end ......
check data server node data state by dml storage fevent log start ......
check data server node data state by dml storage fevent log end ......
check data server node data state end ......
check cluster data state end ......
delete all fevent log on replace nodes start ......
delete ddl event log on node 192.168.174.62 start
delete ddl event log on node 192.168.174.62 end
delete dml event log on node 192.168.174.62 start
delete dml event log on node 192.168.174.62 end
delete dml storage event log on node 192.168.174.62 start
delete dml storage event log on node 192.168.174.62 end
delete all fevent log on replace nodes end ......
sync metedata start ......
sync coordinator metedata start ......
sync coordinator metedata end,spend time 0 ms ......
sync data server metedata start ......
node: 192.168.174.61 data server build data packet successed
copy data server table from 192.168.174.61 to 192.168.174.62 successed
node: 192.168.174.61 data server remove data packet successed
sync dataserver metedata end,spend time 14490 ms ......
sync metedata end ......
set sync data flag start ......
get database and tables information start ......
get database information start ......
get database information end
get tables information start ......
get tables information end.
get database and tables information end,spend time 1934 ms ......
create database and set table dml storage event start ......
create database start ......
create database end ......
set data restorage flag start ......
set data restorage flag end
node [192.168.174.62] set table dml storage event count: 59
set table dml storage event totally count: 59
create database and set table dml storage event end,spend time 17 ms ......
set sync data flag end ......
restore cluster mode start ......
restore cluster mode end ......
restore node state start ......
restore node state end ......
all nodes replace success end
replace nodes spend time: 19362 ms
Replace gcluster nodes successfully.
4节点会有一段时间处于readonly状态,故障节点为REPLACE状态。
5、集群恢复,故障节点为OFFLINE状态
6、节点上线,设置需要同步状态
能看到都是dmlstorageevent。 会从备份节点搬迁数据。
打补丁!!!如果集群打过补丁,切莫忘记。
《南大通用GBase 8a 强制节点离线和节点替换replace》有1条评论
评论已关闭。