目录导航
原因
部分节点数据主副本不一致导致。
已知触发原因包括断电,OS重启,数据库服务宕机(包括BUG)或重启,网络断开或操作timeout,CPU或磁盘太繁忙导致timeout,磁盘损坏、磁盘空间满、文件系统损坏,人为误操作文件被覆盖或删除等。
解决
如节点离线,或者服务为CLOSE,先将节点的服务恢复。
如服务已经恢复,数据库会自动进行同步,具体过程可以查看后面的排查过程
排查样例
查看不一致的信息
gcadmin showdmlevent
gcadmin showddlevent
gcadmin showdmlstorageevent
比如
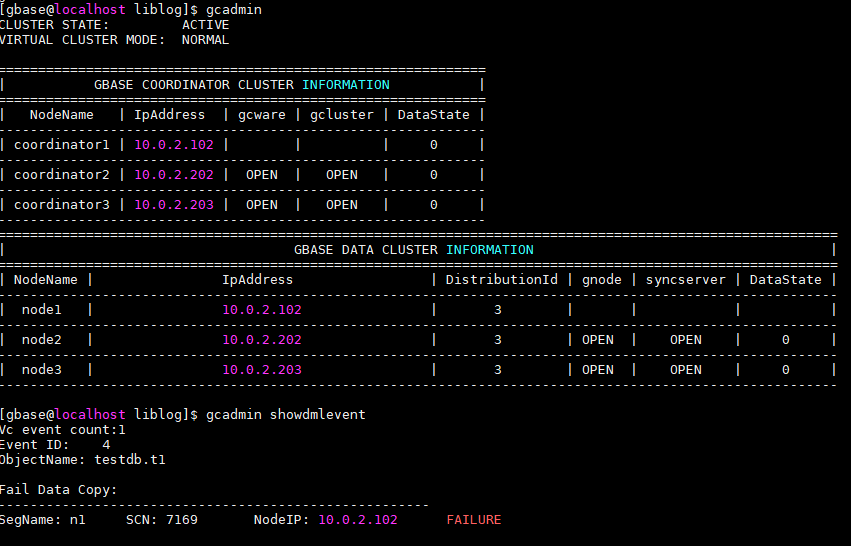
可以看到有1个不一致的情况,是testdb.t1表,处于10.0.2.102的n1分片。
判断故障原因和类型
而根据上面的信息,【当前是因为集群服务离线了】,要先解决服务问题。具体请根据实际故障情况解决。
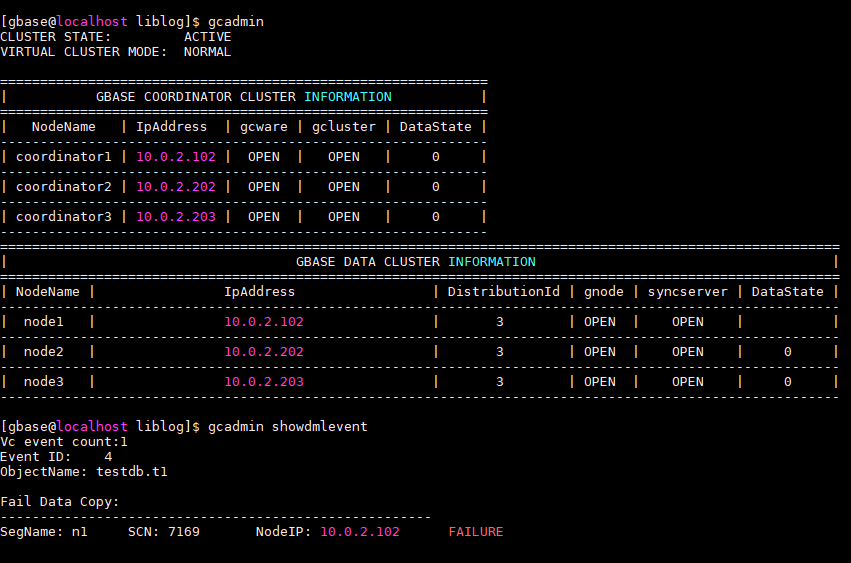
然后我们去10.0.2.102节点,查看数据自动同步的情况。需要转到gnode节点目录,比如 /opt/gbase/gnode/log/gbase/
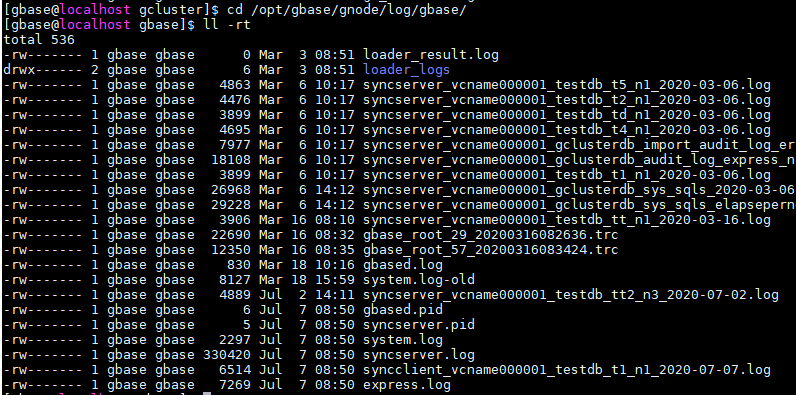
可以看到比较新的syncclient开头的,包含testdb_t1_n1字样的日志文件
排查故障自动恢复日志
我看看一下文件内容,看同步进展

同步成功标志
注意最末尾的
Sync Table vcname000001.testdb.t1_n1 Success
字样(V8版本没有vcname000001字样,这是V9虚拟集群才有的),表示本次同步是成功的,也就是不一致的状态,应该恢复了。查看集群状态
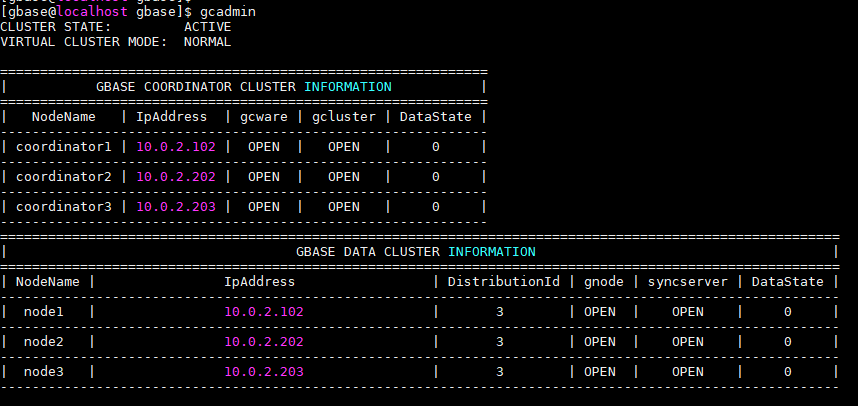
已经恢复。
同步失败排查
如果日志显示恢复失败,需要查看这部分日志的报错部分,是什么原因导致无法自动恢复的。排除硬件和操作系统故障,比如文件损坏,空间慢,目录权限不对等情况外,其它原因可能是数据库配置问题,或者bug。
还有一种情况,如果这个表是一个频繁加载的表,在恢复过程中,又有新数据入库,则虽然本次同步成功了,但再次检查时,还是发现数据不一致,也就造成了这张表,会一直在同步,且每次都成功,但就是【追不上】。
可以强行停了这个表的加载一段时间,等同步完成且不一致标志消失后,再恢复加载或变动。
也可以参考
GBase 8a 表同步一直完不成,同步强制锁表的参数解决同步一直追不上加载
其它节点同步日志也需要排查
在集群层的日志里,可以看到恢复的记录(gcrecover_taskrecord.log)和调度过程(gc_recovery.log)。注意如果有多个管理节点,恢复记录会出现在任何一台上面。
如上可以看到,eventid=4,目标testdb.t1, n1分片的同步。在在2020-07-07 08:50:12.256完成。
同步调度过程
在gc_recovery.log里有整个调度过程
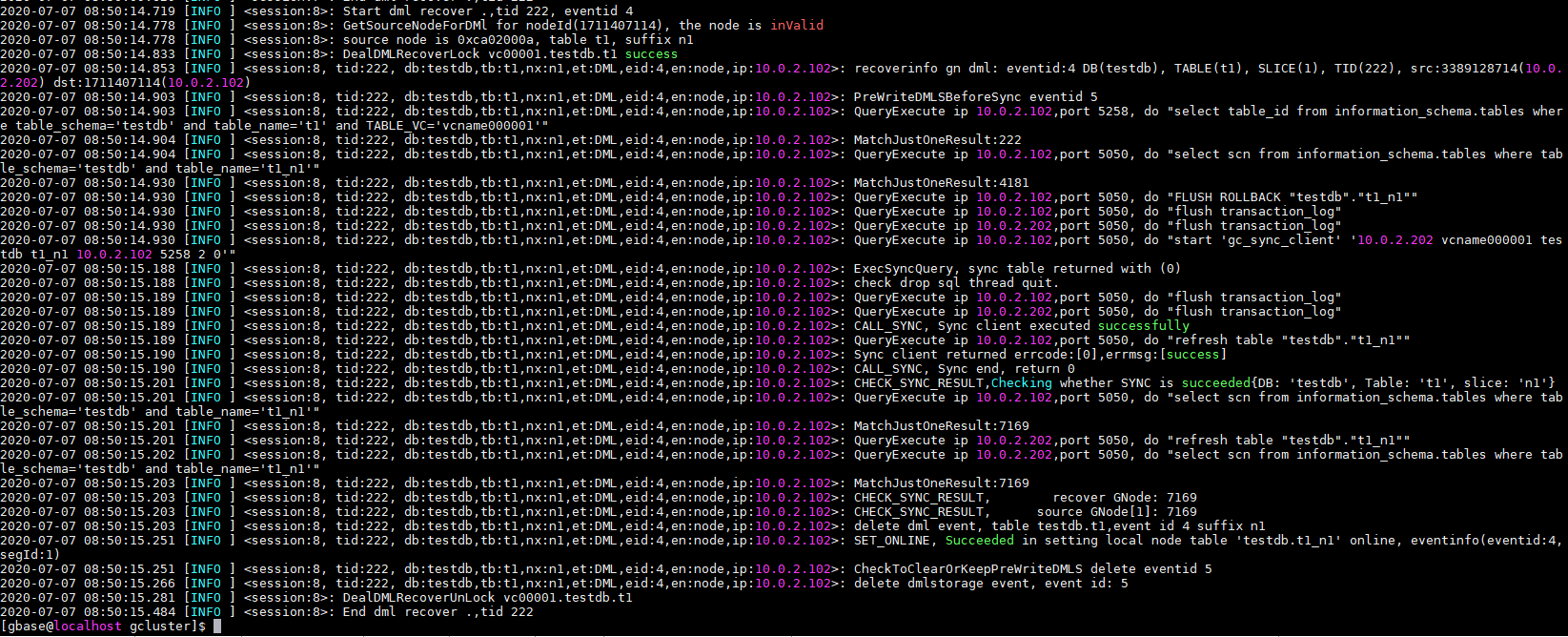
其中第一行表名调度的是eventId=4
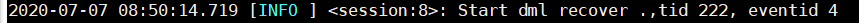
请注意其中session:8字样,如果有多个同步一起调度,日志是混在一起的,可以通过这个特征字符串来过滤日志,确保看到的是一个调度session的过程。
DDLevent处理
如果dmlevent 和 dmlstorageevent处理失败,会继续处理后面的eventid, 但对于ddlevent, 则会一直处理eventid最小的那个。
如果一张表记录了多个eventID, 会先做最小的那个,后面的event在处理时,会被忽略掉,因为有更小的event要处理。
很常见的