本文介绍一次因业务需要做出参数调整后,导致另外部分业务性能出现性能异常的案例。包括排查过程和分析过程。
目录导航
现象
现场反馈一个SQL跑了3个多小时了还没有结束。同时,集群有多个SQL出现耗时远超平时。
现场为862版本集群。正准备升级到953版本。由于发生了该问题,客户要求分析原因,是否953也有该问题。
排查
查看集群运行的SQL
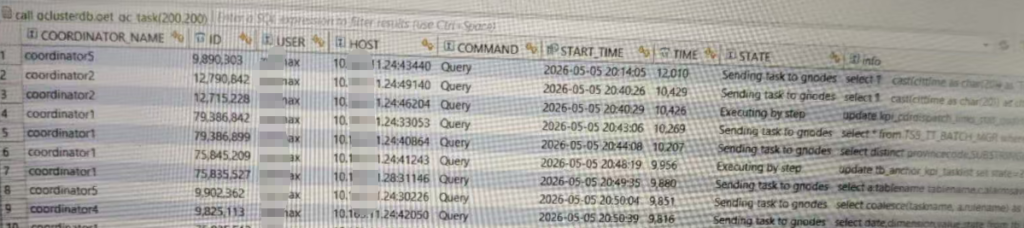
最长的运行12000秒,3个多小时了,后面还有个10000多秒的。看SQL像用户重复执行的。
select COORDINATOR_NAME, ID, user, host, command, start_time, time, state, substring(info,0,100) info from information_schema.COORDINATORS_TASK_INFORMATION where command='query' and time >=0 order by time desc limit 10;该SQL是20:14:05开始执行
查看计算节点SQL
计算节点执行时间12000秒,和集群层的对应上了。另外,所有SQL全部在node3节点上,判断该节点是问题原因。
select NODE_NAME, ID, user, host, command, start_time, time, state, substring(info,0,100) info from information_schema.GNODES_TASK_INFORMATION where command='query' and info is not null and info not like '%information_schema.processlist%' order by time desc limit 10;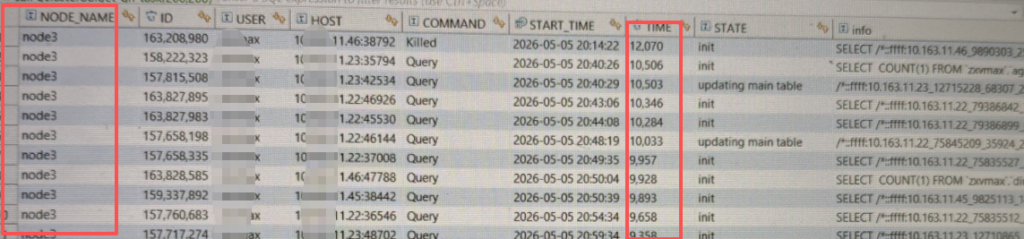
登录node3,查看是否存在环境报错
未看到环境报错。
dmesg | grep -i error
查看操作系统日志
确实正常,未见到硬件或操作系统类报错信息。
tail /var/log/messages
查看内存
内存充足,没有使用SWAP。
free -g
查看系统资源是否存在持续繁忙
可以看到磁盘持续100%繁忙,且每秒写入磁盘900MB/s, 存在超大量的持续写入。
iostat -xdc 1
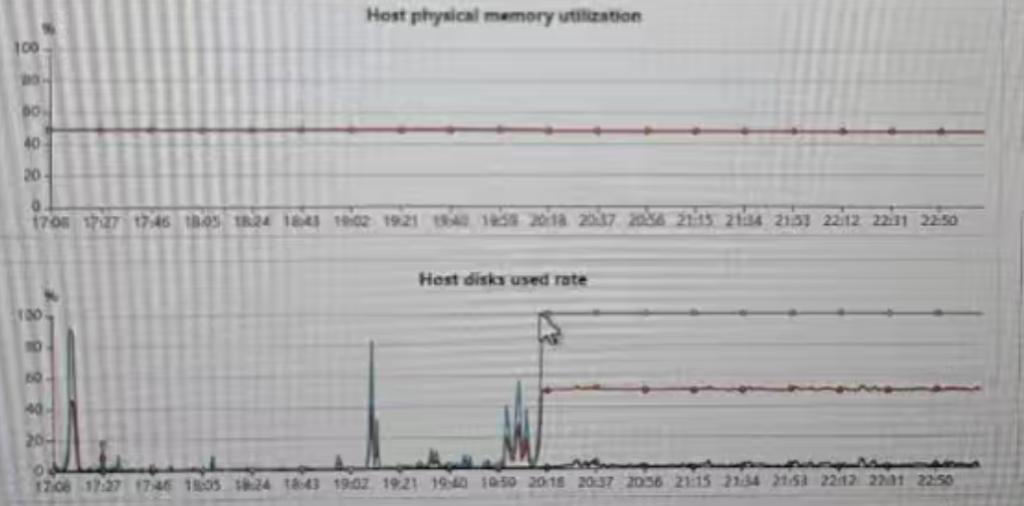
查看用户操作系统监控历史
发现20点后,出现了磁盘使用率的突然增加,且一直持续到现在。该时间与SQL开始执行时间对应上。
如下是OS资源监控记录。
查看数据库临时目录
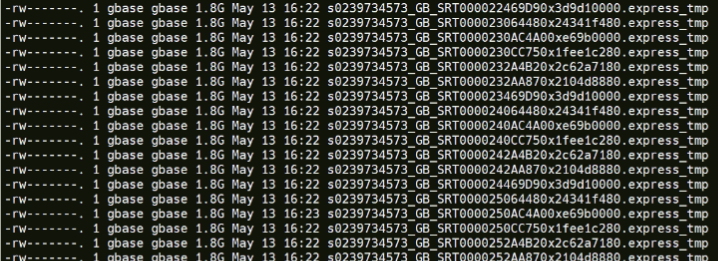
发现几千个临时文件,类型是SRT排序用的。文件大小10TB+。
du -sh 数据库按照目录/gnode/tmpdata/*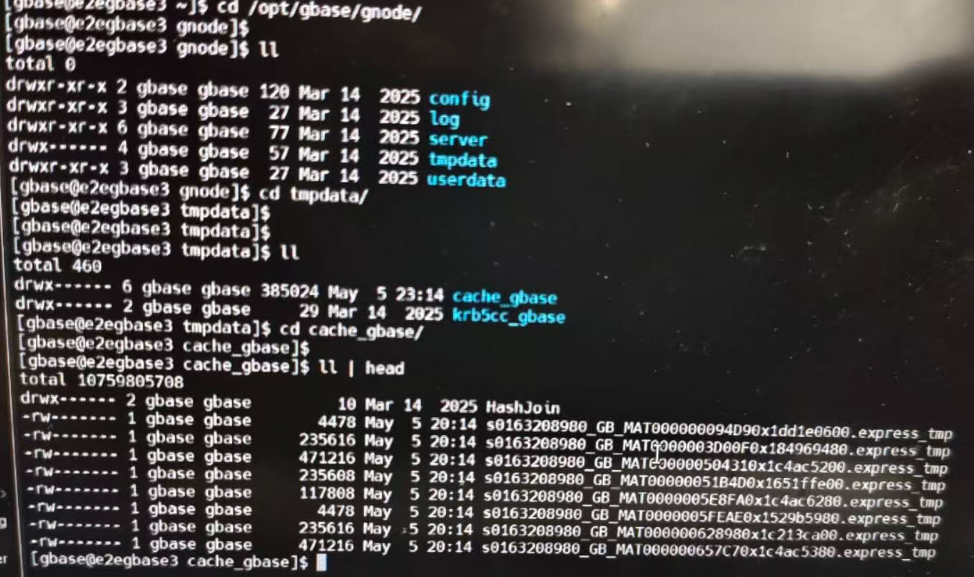
业务SQL性能排查
确认业务SQL
一个简单TOPN的SQL。带order 排序, limit 1000行。外层没有group by。
select
xxxx
from (
...
)a left join
(
...
)b on ... left join
(
...
)c on
order by xxx
limit 1000内部是3个子查询的 left join,
逐层确认三个join表的行数
采用create table tmp_a as select ...的方式,分别创建了三个子查询的临时表。
其中第一个子查询是主表group by,20亿行,结果集20万行。
第二个子查询是个维度表 distinct,结果集2000行。
第三个子查询是个2表left join group by , 结果集也是2万行。
逐个确认最终结果集行数
简化SQL,去掉所有无用的投影列,直接count(*)
select
count (*)
from a left join
b on ...
第一个left join结果集为20万行,耗时10秒以内,未发生笛卡尔积的情况。
select
count (*)
from a left join
b on ... left jpin
c on 第二个left join 结果集依旧是20万行,耗时10秒以内。
也就是,该SQL不是大结果排序导致的,那为什么20万行排序,而且是带limit 的 order, 需要产生那么多的SRT中间数据源呢?
确认哪个投影列导致了性能问题
将count(*)逐个改回原始SQL,最后发现设计到临时C表的一个列时出现问题。
查看临时表结构
查看临时表C的表结构,发现该列是longtext类型。
查看原始SQL
发现临时表C的该列,有如下的计算 group_concat(xxx), 也就是要把列变成行。
查询max(length(xxx)),该列原始表的值最大只有10个字符,为啥生成的中间表是longtext呢?
查看数据库参数
show variables like '%group_concat_max_len%’返回值是1M,而不是默认的32K。
问题定位
分析
参数由来
group_concat的执行结果默认是32K(对应uft8 字符集10922个字符)。如果执行结果超过了32K,则会报错(Aggregation function group_concat overflow)
参考如下文章:南大通用GBase 8a集群常见报错 Aggregation function group_concat overflow
为了解决这个问题,数据库增加了一个参数group_concat_max_len,该参数是该函数允许的最大长度。用户设置成了1MB。
longblob类型由来
如果要将直接结果保存到【临时中间表】里,类似create table tmpXXX as select, 那么需要【提前】评估该列的宽度,而不是执行完成了再建表。 而该列的参数值为1M, 超过了varchar最大允许的32K, 于是字段类型评估为longtext。
排序的磁盘占用原因
排序时,参与排序的投影列要先物化,
数据需要提前分配内存来保存物化数据。在862版本里,是根据表结构来分配内存的。longtext的最大长度为64MB,内存肯定不够,于是写入到磁盘临时文件中。
20万行,每行最少64MB,两者相乘,需要12.2TB。 于是,磁盘上出现了10TB+的临时文件写入。按照每秒1GB写入,也需要3.4个小时。
为什么只有node3上有这么大的临时文件
查看主表SQL, 其中的group by clttime, cell_id。 其中cell_id是蜂窝小区编号,相对多。 而clttime是采集日期,一天中都是一个值。而该表又是随机分布表,没有hash列,所以group by时,第一个列被选成了分布列,最终数据都落在一个节点上。
此处可以将cell_id列放前面来规避这种情况。
或者将所有的group by列一起作为hash分布列,但这会影响性能,参数为
_t_gcluster_hash_redistribute_groupby_on_multiple_expression参考:南大通用GBase 8a做distinct、group和join时避免严重数据倾斜导致的性能问题
参数能调整吗?
该参数是因为其他业务确实有超过32K的group_concat结果才调高,但会导致其他一些SQL在该参数下执行异常,从全局参数角度看,参数值只有1个,这无法完美匹配所有场景。
解决方案
调整SQL
干预group_concat的执行结果宽度评估,比如在外面加上substr
substr(group_concat(xxx),0,1000)这样,结果宽度就不会超过1000个字符,中间表的列类型就是varchar(1000)
现场采用了本方案,最终30秒以内完成。
使用hint
gbase 8a可以通过hint动态调整session级别的参数值,比如
select /*+group_concat_max_len(3000)*/ ...该hint就是指定该SQL的最大group_concat宽度不会超过3000字节,也就是1000个utf8字符。
升级95版本
在95版本里,内存分配不是按照字段的最大宽度,而是先根据当前数据分配一块,如果不够再继续分配。这样减少了内存的实际占用,对应的中间结果集也更接近实际磁盘占用。
总结
由于参数调整,导致数据库内存评估大,写入了大量的磁盘中间文件用于排序,从而导致该节点IO资源被持续繁忙,导致其他正常SQL也性能下降。
同时,一个参数不可能适应所有场景,部分重要的业务SQL可以用hint方式设置适合自己的参数。